
The discoverability gap
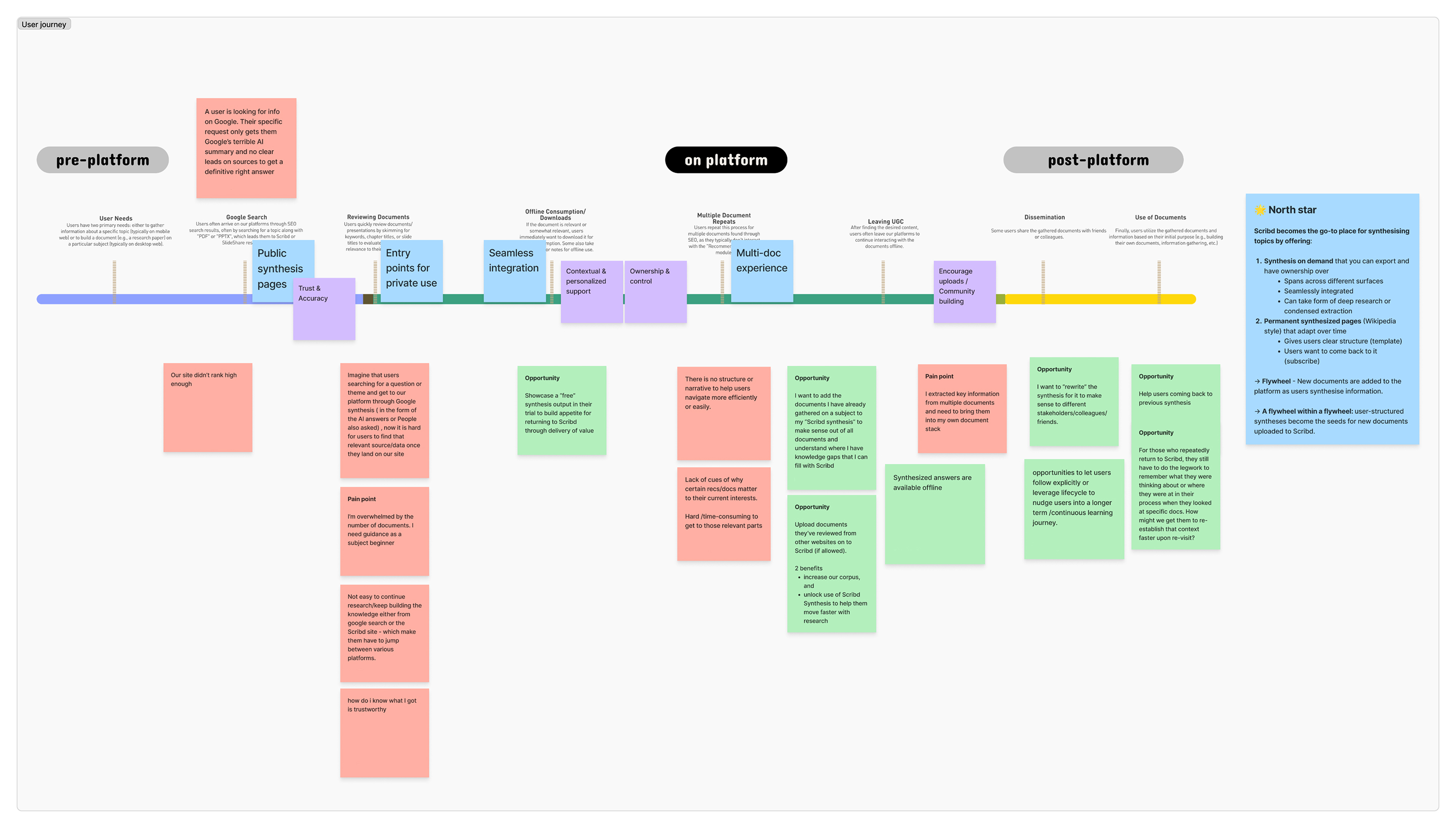
Before committing to a direction, I brought together product, ML, and design to map out where users were running into friction when trying to find trustworthy content for a specific task, and generate experiment ideas. The idea of AI-powered wiki pages won a lot of enthusiasm, as they addressed both pressures at once: giving users the synthesized answers they were looking for, and giving Scribd a presence in AI-generated search results.
How the prototype did the research
To validate the idea quickly without building the real thing, I built functional prototypes in code that let us swap out page content based on a user's interests in real-time during research sessions, so participants were reacting to content that was actually relevant to them, not placeholder copy.
That turned out to unlock a lot more than just concept validation:
That turned out to unlock a lot more than just concept validation:
- Authentic reactions at the concept stage. Because users were genuinely engaged with the content, we could observe real navigation behaviour: which trust signals they were looking for, how they scanned for relevance, and when they wanted to go deeper.
- Scope confidence under deadline pressure. When tradeoff decisions came up near launch, those insights gave the team a shared basis for what to cut and what interface elements to protect.
- A synchronous design and ML loop. Instead of waiting for frontend development to finish before previewing generated content, I used the prototypes to review output from the ML pipeline in production layouts while the frontend was still being built. We could spot quality differences, adjust reasoning parameters, and make formatting decisions in parallel, keeping us on track without adding engineering cycles.
Updating prototypes during user research sessions with relevant content in near real time.
A new direction for Scribd
The result is an ever-growing collection of AI-synthesized wiki pages. The impact went further than the feature itself.
A scalable architecture, not a one-off feature.
Validating user expectations early meant the architecture was built to scale. Inline citations, content backlinking, and trust scaffolding were part of the foundation, making it straightforward to extend the system to Home, Search, and other site surfaces.
A strategic pivot for Scribd's discovery model.
Thinking holistically about the user journey, on and off platform, helped reshape how the broader team thought about discovery. Multi-content synthesis went from being an experiment to becoming a cornerstone of how Scribd's product direction evolved.
A new way of working between design and ML engineering.
The synchronous loop between design and ML engineering, running in parallel from the start rather than sequentially, became the template for how future innovation projects were run at Scribd.
A scalable architecture, not a one-off feature.
Validating user expectations early meant the architecture was built to scale. Inline citations, content backlinking, and trust scaffolding were part of the foundation, making it straightforward to extend the system to Home, Search, and other site surfaces.
A strategic pivot for Scribd's discovery model.
Thinking holistically about the user journey, on and off platform, helped reshape how the broader team thought about discovery. Multi-content synthesis went from being an experiment to becoming a cornerstone of how Scribd's product direction evolved.
A new way of working between design and ML engineering.
The synchronous loop between design and ML engineering, running in parallel from the start rather than sequentially, became the template for how future innovation projects were run at Scribd.